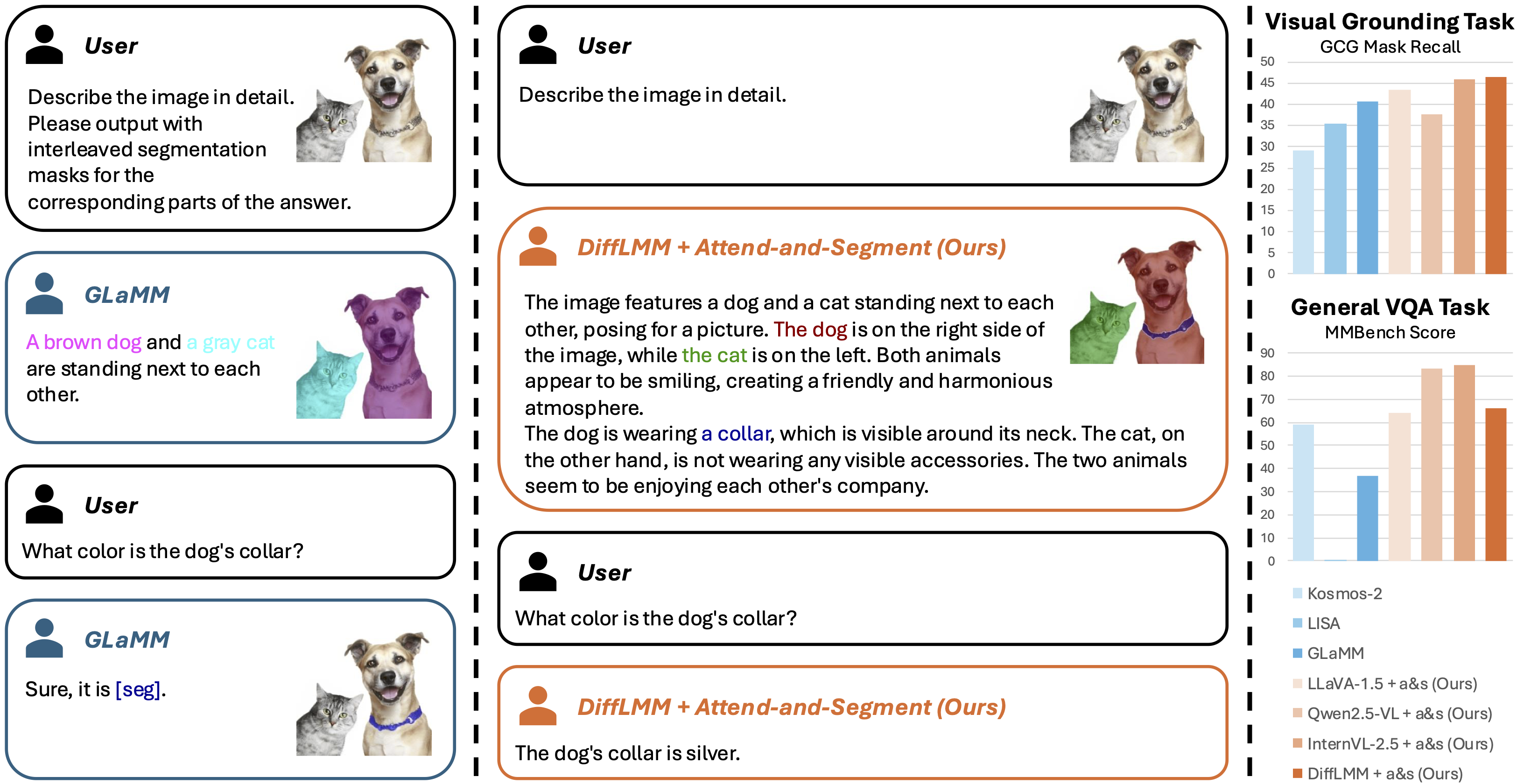
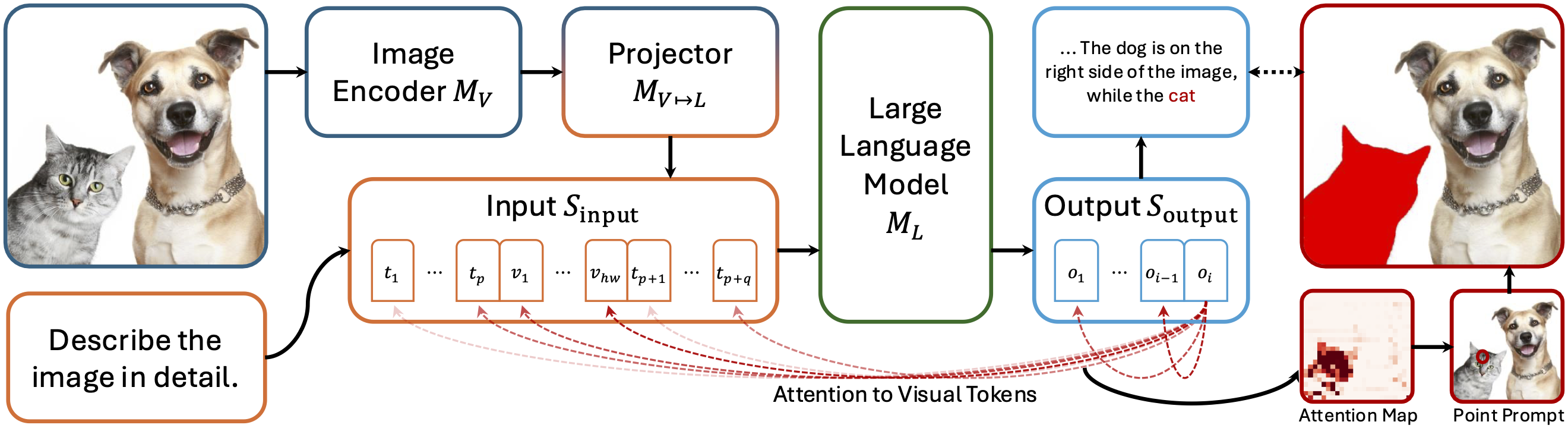
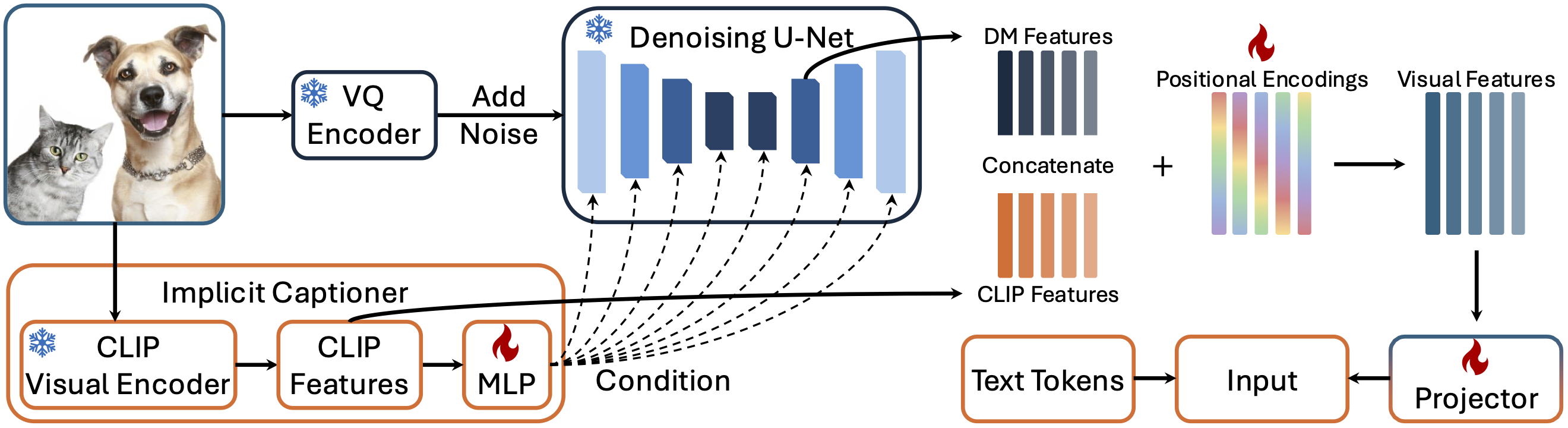
Current large multimodal models (LMMs) face challenges in visual grounding, which requires the model to relate language components to visual entities. Contrary to common practice that fine-tunes LMMs with additional grounding supervision, we find that grounding ability can be implicitly learned by LMMs to some extent without explicit grounding supervision that sacrifices general conversation ability. To unlock this grounding ability, we first introduce a training-free strategy "Attend-and-Segment," which analyzes the attention within an off-the-shelf LMM to provide a point prompt to a segmentation model (e.g., SAM) and perform pixel-level segmentation. This strategy instantly enables visual grounding for existing LMMs while keeping their original conversation ability intact. Second, motivated by vision-language alignment and localized features embedded in diffusion models, we propose DiffLMM—a LLaVA-like LMM that utilizes a diffusion-based visual encoder instead of the standard CLIP visual encoder. This design enhances the implicit grounding ability without changing the training data. Without being constrained by the biases and limited scale of grounding-specific supervision data, our approach enables strong visual grounding while preserving general conversation capabilities. We achieve competitive performance on both grounding-specific and general visual question answering benchmarks, compared with grounding LMMs and generalist LMMs, respectively. Notably, we achieve a 46.4 grounding mask recall on grounded conversation generation, outperforming the extensively supervised model GLaMM.